
An excellent way to put their newfound skills could by allowing them to work on Machine Learning Projects for Students with Python which will be quite exiting opportunity for the students across varied domains. This chapter goes deep inside predictive modeling, which is just scratching the surface of what machine learning can do, from predicting electricity consumption to optimizing smart traffic systems. Break, where students run code to analyze datasets and build models, Informing evaluation This module includes instructions for real-world applications on each aspect of analyzing dataset, model constructs, or evaluating performance improvements. Through Python, readers discover the potential for drastically increased system efficiencies and data-oriented concepts and examples: including hands-on examples that can be applied to students’ own projects in class disruption.Comment by consultant Idan Gabriel Case– prompt_content –By understanding the way Python is marked by great gains in effectiveness and practical ways of working with data-driven concepts this book is relevant to all of us.
Machine Learning Project With Source Code
1.Energy Consumption Forecasting
2.Environmental Monitoring and Sustainability
3.Automation in Manufacturing
4.Smart Traffic Systems
1.Energy Consumption Forecasting
The first use case surrounds machine-learning powered energy consumption forecasting, a process that tries to accurately predict the amount of electricity (and in a broader sense energy) companies will produce, distribute or consume at some point in the future. This is important for city planning, for efficiency in the energy system and a move toward sustainable energy.
Learners will proceed to build basic models for machine learning on historical energy data with reference to factors like weather, time of the day and seasonality to predict energy demand in this section. It introduces readers with a dataset to perform data processing, feature selection and the implementation of a Linear Regression model further showing the influence of machine learning on energy savings.
Problem Statement
The objective in this machine learning project for students is to predict the future energy consumption using historical data along with time of day, temperature, day of week and season (coming together as weather data) as the factors. The goal is to create a model that can predict the demand for energy and, therefore, help you make better decisions about planning energy usage. This project provides students with real-world practice designing impactful energy system optimization solutions, thus making it an excellent item in any machine learning project ideas list for students.
Requirements
- Data Exploration: Start by analyzing the dataset to understand how various factors, such as temperature and time, affect energy consumption. Look for patterns or trends in the data.
- Feature Engineering: Enhance the model by creating or modifying features. Consider how factors like the time of day or day of the week influence energy usage, and explore potential interactions between variables.
- Model Building: Develop a Linear Regression model to predict energy consumption. Experiment with different feature combinations to find the most effective model.
- Evaluation: Measure the model’s accuracy using metrics like Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE). Lower errors reflect better predictive performance.
- Interpretation: Analyze the results to understand how each feature impacts energy consumption. This information is crucial for making informed decisions in energy management.
Data Exploration
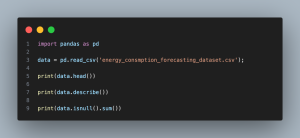
- import pandas as pd: Imports the pandas library, which is a powerful data manipulation tool.
- data = pd.read_csv(‘energy_consumption_forecasting_dataset.csv’): Reads the CSV file containing the energy consumption dataset into a pandas DataFrame.
- print(data.head()): Prints the first five rows of the dataset to provide a quick look at the data structure.
- print(data.describe()): Generates descriptive statistics that summarize the central tendency, dispersion, and shape of the dataset’s distribution.
- print(data.isnull().sum()): Checks and prints the number of missing values in each column.
Feature Engineering
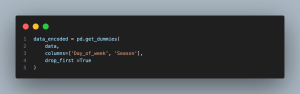
data_encoded = pd.get_dummies(data, columns=[‘Day_of_Week’, ‘Season’],
drop_first=True): Creates dummy variables for “Day_of_Week” and “Season” columns, excluding the first category to avoid multicollinearity. This process is essential for preparing categorical variables for machine learning models.
Model Building
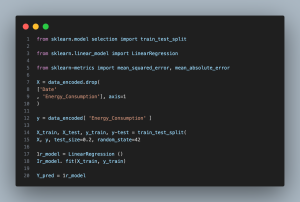
- from sklearn.model_selection import train_test_split: Imports the function to split datasets into training and testing sets.
- from sklearn.linear_model import LinearRegression: Imports the Linear Regression model.
- from sklearn.metrics import mean_squared_error, mean_absolute_error: Imports functions to compute evaluation metrics.
- X = data_encoded.drop([‘Date’, ‘Energy_Consumption’], axis=1): Prepares the feature matrix by excluding the date and target variable.
- y = data_encoded[‘Energy_Consumption’]: Defines the target variable.
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42): Splits the dataset into training and testing sets.
- lr_model = LinearRegression(): Initializes the Linear Regression model.
- lr_model.fit(X_train, y_train): Trains the model on the training set.
- y_pred = lr_model.predict(X_test): Predicts energy consumption for the test set.
Evaluation
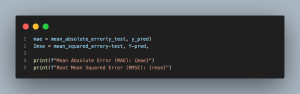
- mae = mean_absolute_error(y_test, y_pred): Calculates the Mean Absolute Error (MAE) between the actual (y_test) and predicted (y_pred) energy consumption values. MAE provides a straightforward measure of prediction accuracy, representing the average absolute difference between actual and predicted values.
- rmse = mean_squared_error(y_test, y_pred, squared=False): Calculates the Root Mean Squared Error (RMSE) between the actual (y_test) and predicted (y_pred) values. RMSE is a measure of the average magnitude of the errors. The squared=False parameter returns the square root of the mean squared error, converting it from Mean Squared Error (MSE) to RMSE.
- print(f”Mean Absolute Error (MAE): {mae}”): Prints the calculated MAE to the console, providing a simple interpretation of the average error magnitude per prediction.
- print(f”Root Mean Squared Error (RMSE): {rmse}”): Prints the calculated RMSE, giving an indication of the prediction accuracy. RMSE penalizes larger errors more than MAE, making it useful when large errors are particularly undesirable.
Plotting and Visualization
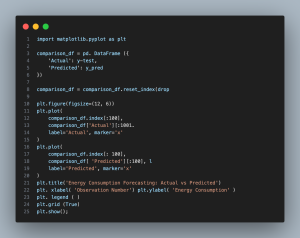
- import matplotlib.pyplot as plt: Imports the matplotlib library for plotting.
- comparison_df = pd.DataFrame({‘Actual’: y_test, ‘Predicted’: y_pred}).reset_index(drop=True): Creates a new DataFrame containing actual and predicted values and resets the index for plotting.
- plt.figure(figsize=(12, 6)): Sets the figure size for the plot.
- plt.plot(…): Plots both actual and predicted energy consumption values for the first 100 observations.
- plt.title(…), plt.xlabel(…), plt.ylabel(…): Sets the title and labels for the plot.
- plt.legend(): Adds a legend to the plot.
- plt.grid(True): Adds a grid to the plot for better readability.
- plt.show(): Displays the plot.

This built-in visualization tool now allows you to track energy consumption by an existing model over time: — Take the data for each prediction and the corresponding actual value. Real data is represented by the blue line and predicted values are in orange. Though the two are slightly offset from one another, together they form a pattern line, and any model following this relatively straight line should be intriguing. But there are still times when demand predictions come in too high or too low, particularly in greater energy use scenarios. The model is good at taking low values, but in peaks it does however notice the decrease in accuracy.
In the case of students who are working on Machine Learning Projects the improved model is obtained by either adding better features, tuning parameters or trying more advanced techniques to make it run most accurately.
2. Environmental Monitoring and Sustainability
The advantages of machine learning are quite evident right, and these in combination with environmental science provide key tools for addressing the pressing challenges such as climate change, pollution.getResource depletion. The Machine Learning Projects for Students at the property be sending an algorithm to Decision Trees that serves for making predictions by analyzing environmental data. And some have been used to determine air quality and locate pollutants or identify recyclable materials for better waste management, thereby reducing environmental damage.
Machine learning gives us the ability to predict both environmental trends and policies that can move us toward sustainable progress. In experimenting with weather data, pollution index data and also studying recyclable data from their real world datasets, students could seen learn patterns that may be consequential for the future of environmental monitoring and protection.
Problem Statement:
Our goal is to use machine learning to analyze environmental data for monitoring and promoting sustainability. By using intermediate algorithms, we can predict air quality and classify waste types for better recycling. This is essential for tracking pollution and improving waste management, both crucial for protecting the environment and conserving resources.
Requirements:
1. Understanding Machine Learning’s Role: Discuss the application of machine learning in environmental monitoring, emphasizing its capability to handle large datasets for predicting air quality and assisting in waste management.
2. Dataset Analysis: Utilize a dataset containing various environmental parameters such as pollutant levels and weather information, alongside characteristics of waste that can be recycled. The dataset is available at: https://files.fm/u/3gg6vfcwp5
3. Decision Trees Application: Employ Decision Trees to predict air quality indices based on pollutant levels, weather conditions, and other relevant factors. Additionally, explore the classification of waste types for recycling.
4. Code Development: Develop Python code step-by-step to address these tasks. This includes data preprocessing, model training using Decision Trees, and evaluation of the model’s performance.
5. Result Interpretation: Execute the code and discuss the results, emphasizing the model’s accuracy and its implications for real-world application. Consider how the model’s performance metrics align with the objectives of the project and potential impact on stakeholders.
Data Exploration
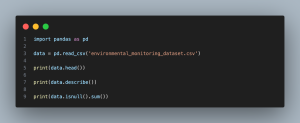
- import pandas as pd: Imports the pandas library for data manipulation.
- data = pd.read_csv(‘environmental_monitoring_dataset.csv’): Reads the CSV file containing the environmental monitoring dataset into a pandas DataFrame.
- print(data.head()): Displays the first few rows of the dataset to understand its structure and content.
- print(data.describe()): Generates summary statistics for each numerical column in the dataset, providing insights into central tendency, dispersion, and distribution.
- print(data.isnull().sum()): Checks for missing values in each column of the dataset and prints the total count of missing values per column.
Data Preprocessing
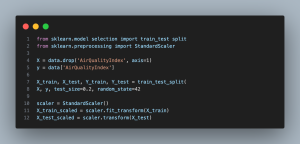
- from sklearn.model_selection import train_test_split: Imports the train_test_split function from scikit-learn, which is used to split the dataset into training and testing sets.
- from sklearn.preprocessing import StandardScaler: Imports the StandardScaler class from scikit-learn, which is used to standardize features by scaling them to have a mean of 0 and a standard deviation of 1.
- X = data.drop(‘AirQualityIndex’, axis=1): Separates the features (independent variables) from the target variable (AirQualityIndex) in the dataset.
- y = data[‘AirQualityIndex’]: Assigns the target variable (AirQualityIndex) to the variable y.
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42): Splits the dataset into training and testing sets, with 80% of the data used for training and 20% for testing. The random_state parameter ensures reproducibility of the split.
- scaler = StandardScaler(): Initializes a StandardScaler object to standardize the features.
- X_train_scaled = scaler.fit_transform(X_train): Standardizes the training features by fitting the scaler to the training data and transforming it.
- X_test_scaled = scaler.transform(X_test): Standardizes the testing features using the same scaler fitted to the training data.
Data Preprocessing
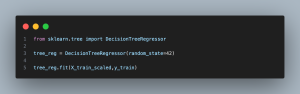
- from sklearn.tree import DecisionTreeRegressor: Imports the DecisionTreeRegressor class from scikit-learn, which is used to build a decision tree model for regression tasks.
- tree_reg = DecisionTreeRegressor(random_state=42): Initializes a DecisionTreeRegressor object with a specified random seed for reproducibility.
- tree_reg.fit(X_train_scaled, y_train): Trains the decision tree model on the standardized training features (X_train_scaled) and the corresponding target variable (y_train). The model learns to predict the Air Quality Index based on the environmental features provided.
Data Preprocessing
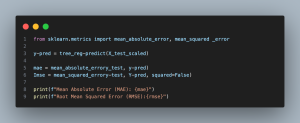
- from sklearn.metrics import mean_absolute_error, mean_squared_error: Imports the mean_absolute_error and mean_squared_error functions from scikit-learn, which are used to calculate evaluation metrics for regression tasks.
- y_pred = tree_reg.predict(X_test_scaled): Makes predictions on the scaled testing features (X_test_scaled) using the trained Decision Tree model (tree_reg).
- mae = mean_absolute_error(y_test, y_pred): Calculates the Mean Absolute Error (MAE) between the actual Air Quality Index values (y_test) and the predicted values (y_pred).
- rmse = mean_squared_error(y_test, y_pred, squared=False): Calculates the Root Mean Squared Error (RMSE) between the actual and predicted values. The squared=False parameter returns the RMSE instead of the Mean Squared Error (MSE).
- print(f”Mean Absolute Error (MAE): {mae}”): Prints the calculated MAE to assess the average absolute difference between the actual and predicted values.
- print(f”Root Mean Squared Error (RMSE): {rmse}”): Prints the calculated RMSE to evaluate the model’s prediction accuracy and error magnitude.
Visualization of Predictions
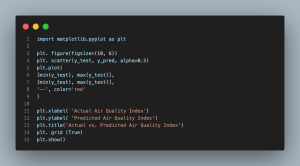
- import matplotlib.pyplot as plt: Imports the matplotlib library for data visualization.
- plt.figure(figsize=(10, 6)): Initializes a new figure with a specified size for the plot.
- plt.scatter(y_test, y_pred, alpha=0.5): Creates a scatter plot of the actual Air Quality Index values (y_test) against the predicted values (y_pred). The alpha parameter controls the transparency of the data points.
- plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], ‘–‘, color=’red’): Adds a diagonal dashed line representing perfect predictions, where the actual and predicted values are equal.
- plt.xlabel(‘Actual Air Quality Index’): Sets the label for the x-axis.
- plt.ylabel(‘Predicted Air Quality Index’): Sets the label for the y-axis.
- plt.title(‘Actual vs. Predicted Air Quality Index’): Sets the title of the plot.
- plt.grid(True): Adds a grid to the plot for better readability.
- plt.show(): Displays the plot.

The scatter plot compares actual Air Quality Index (AQI) values to the predicted values from a machine learning model. Each point indicates how much the prediction was off by, with a red dashed line to indicate perfect accuracy. The more tightly points are close to this line, the better the model will predict.
This plot depicts a linear regression line, indicating that the model is relatively accurate but shows some error where the points differ from the line. These outliers can be used as a feedback to find regions that need tuning in the model or maybe test a better algorithm.
Students doing Machine Learning Projects should pay attention to this plot as it gives them a good picture of the role of Ki ( koh ) like models including Decision Trees in environmental monitoring particularly for predicting air quality —a critical aspect of sustainability and resource conservation.
3. Automation in Manufacturing
Manufacturing Automation is Changing the Way We Design, Build, and Ship Products The move towards extensive digitization is facilitated by the use of machine learning to increase production efficiency, minimize plant downtime and predict maintenance requirements with a much greater degree of certainty. All of this is very important for the tuning of production and the reduced costs.
This section focuses the application of cutting edge machine learning techniques such as Random Forests to predict when individual machines will fail and require maintenance. We will leverage a dataset of machine performance metrics (i.e., temperature, vibration, noise and operational hours) to understand how these factors influence the health score of a machine.
In the Machine Learning Projects for Manufacturing, you will become adept at performing data exploration, feature engineering as well build predictive models using advanced algorithms such Random Forests and Neural Networks that deals with Non-linearly structured data and avoid over fitting. This use case illustrates the future of predictive analytics and how it can predict machine failures for proactive maintenance, thus improving operational efficiency by leveraging innovation in the manufacturing industry.
Problem Statement:
In manufacturing, the promise is to improve automation with advanced machine learning techniques. Object of this is to predict Machine failures and Maintainences required as precisely as possible by Random forests and Neural Networks. This process is efficient because it minimizes downtime, maximizes maintenance and results in production without hiccups. These important key performance metrics, including temperature, vibration, noise and operational hours will be scrutinized to identify possible issues earlier before it leading to costly production stops.
Requirements:
1. Understanding Machine Learning’s Role: Investigate how machine learning, including both ensemble methods and neural networks, can be applied in manufacturing automation.
2. Dataset Analysis: Engage with a dataset that mirrors real-world machine performance metrics. This dataset is fundamental for understanding how various operational conditions affect machine health and longevity. The dataset is available at: https://files.fm/u/5nswccnccn
3. Ensemble Methods and Neural Networks Application: Implement Random Forest ensemble methods to construct a model that can predict machine failures, while also employing neural networks for their ability to capture complex patterns. This combined approach aims to leverage the strengths of both methods to optimize prediction accuracy.
4. Code Development: Systematically develop Python code to carry out data preprocessing, model training using both Random Forest and neural networks, and the application of evaluation metrics to gauge the models’ performance.
5. Result Interpretation: Execute the developed code and conduct a thorough analysis of the outcomes. Provide insights into how effectively the used machine learning models identify potential machine failures. Discuss the implications of these predictive models for boosting operational efficiency in manufacturing environments.
Data Loading and Exploration
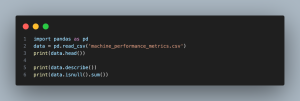
- import pandas as pd: Imports the pandas library, which is essential for data manipulation and analysis.
- data = pd.read_csv(‘machine_performance_metrics.csv’): Reads the CSV file named machine_performance_metrics.csv, containing the machine performance metrics, into a pandas DataFrame. Make sure that the file is located in the current working directory or the specified path is provided correctly.
- print(data.head()): Prints the first five rows of the DataFrame, providing a quick look at the dataset’s structure, including columns and sample values.
- print(data.describe()): Generates descriptive statistics that summarize the central tendency, dispersion, and shape of the dataset’s distribution, excluding NaN values. This helps in understanding the range, median, mean, and quartiles of the numerical variables.
- print(data.isnull().sum()): Checks for missing values across each column and prints the count of missing values. This step is crucial for identifying if any data imputation or cleaning is necessary before further analysis.
Data Preprocessing
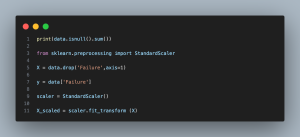
- print(data.isnull().sum()): Rechecks for missing values in each column. This is crucial for ensuring data integrity before proceeding further.
- from sklearn.preprocessing import StandardScaler: Imports the StandardScaler class from scikit-learn, a library for machine learning in Python. Standard scaling is a preprocessing step that normalizes the feature data.
- X = data.drop(‘Failure’, axis=1): Creates a feature matrix X by dropping the ‘Failure’ column from the dataset. This column is the target variable we want to predict.
- y = data[‘Failure’]: Extracts the target variable into a separate vector y, which contains the failure indicators for the machine in the dataset.
- scaler = StandardScaler(): Initializes a new StandardScaler instance for normalizing the feature data.
- X_scaled = scaler.fit_transform(X): Fits the scaler to the feature data and then transforms it. This results in X_scaled, a numpy array where each feature column has a mean of 0 and a standard deviation of 1, making the dataset ready for modeling.
Model Building with Random Forest and Neural Networks
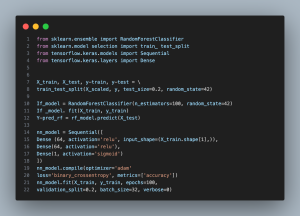
- from sklearn.ensemble import RandomForestClassifier: Imports the RandomForestClassifier, an ensemble method that improves prediction accuracy and controls overfitting by using multiple decision trees.
- from sklearn.model_selection import train_test_split: Utilized to divide the dataset into training and testing sets, essential for evaluating model performance on unseen data.
- from tensorflow.keras.models import Sequential is used to import the Sequential model from TensorFlow’s Keras API, which is a linear stack of neural network layers for creating models layer by layer.
- from tensorflow.keras.layers import Dense imports the Dense layer, which is a fully connected neural network layer where each neuron receives input from all the neurons in the previous layer.
- train_test_split(…): Splits the scaled features (X_scaled) and the target variable (y) into training and testing subsets, with 20% of the data allocated for testing. This split ensures a dataset for model evaluation that is independent of the training process.
- RandomForestClassifier(…): Initializes the Random Forest model with 100 decision trees (n_estimators=100) and a defined random state for reproducibility.
- rf_model.fit(…): Fits the Random Forest model to the training data, allowing it to learn the relationship between features and the target outcome.
- Sequential(…):Initializes a Keras neural network with two 64-neuron hidden layers (ReLU) and a sigmoid output layer for binary classification
- nn_model.compile(…):Prepares the model with Adam optimizer and binary crossentropy loss for binary classification, tracking accuracy.
- nn_model.fit(…):Trains the model for 100 epochs, validating with a data subset, and sets the batch size and output verbosity.
Model Evaluation
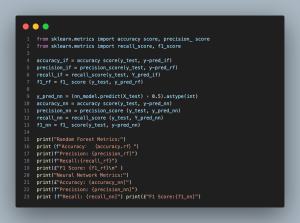
- accuracy_score(y_test, y_pred_rf): Computes the accuracy of the Random Forest model, representing the ratio of correctly predicted observations to the total observations.
- precision_score(y_test, y_pred_rf): Calculates the precision of the Random Forest model, indicating the proportion of correctly predicted positive observations to the total predicted positives.
- recall_score(y_test, y_pred_rf): Determines the recall of the Random Forest model, measuring the ratio of correctly predicted positive observations to all observations in the actual class.
- f1_score(y_test, y_pred_rf): Generates the F1 score for the Random Forest model, providing a balance between precision and recall in a single metric.
- (nn_model.predict(X_test) > 0.5).astype(int): Predicts the outcomes using the Neural Network model, where predictions greater than 0.5 are considered positive (failure), and converts them to integer format for comparison.
- The following lines for the Neural Network (accuracy_nn, precision_nn, recall_nn, f1_nn) mirror the evaluation steps of the Random Forest model, applying the same metrics to assess its performance.
Interpretation and Visualization
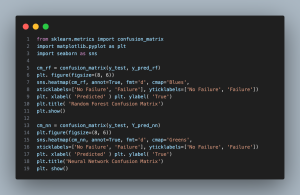
- confusion_matrix(y_test, y_pred_rf) and confusion_matrix(y_test, y_pred_nn) calculate the confusion matrices for the Random Forest and Neural Network models, respectively. These matrices provide a detailed breakdown of predictions across actual and predicted classes.
- plt.figure(figsize=(8, 6)) sets the figure size for the confusion matrix plots.
- sns.heatmap(…): Plots the confusion matrices using seaborn’s heatmap function. This visual representation makes it easier to interpret the model’s performance, showcasing the true positives, false positives, true negatives, and false negatives.
- annot=True displays the data values in each cell of the heatmap.
- fmt=’d’ formats the annotations to be displayed as integers.
- cmap=’Blues’ and cmap=’Greens’ set the color schemes for the Random Forest and Neural Network confusion matrices, respectively.
- xticklabels and yticklabels specify the labels for the x-axis and y-axis, representing the predicted and actual classes.
- plt.xlabel(‘Predicted’) and plt.ylabel(‘True’) label the axes of the plot.
- plt.title(…) adds a title to each confusion matrix plot, distinguishing between the
Random Forest and Neural Network models.

The Random Forest Confusion Matrix shows that the model is going good including identifying ‘No Failure’ cases as near 148 true negatives available and very less misclassifications (shop 229 — naturallyfailure). The F-score for ‘Failure’ is 0.932 when it is asked to detect ‘No Failure’, with a true positive of 41, but its precision rates have several false positives, particularly on political articles.
The model makes mistakes infrequently, 1 false negative (did not catch the failure) and 3 false positives (wrongly thought there was a failure). This indicates that it is highly sensitive and specific, something that is necessary especially in cases where missing one concerning failure could end up costing a large amount of money. A high sensitivity low false positive rate means that the system does not alarm on non-failures.
Thus, the Random Forest model is quite good in predicting and not predicting failure or non-failure, implies high recall and accurate precision. Precisely this balance: An excess of false positives will squander efforts, and an abundance of false negatives means that failures run wild. This is a good balance that the model achieves and thus making it useful for predictive maintenance where when failures are not found its as good as useless.

The Neural Network Confusion Matrix shows excellent performance, correctly predicting ‘No Failure’ 149 times and ‘Failure’ 48 times. There are only a few errors: 1 false negative (failing to detect a failure) and 2 false positives (mislabeling non-failures as failures). This highlights the model’s high precision and recall, making it reliable for predicting machine failures with minimal mistakes.
Both the Neural Network and Random Forest models perform well. The Neural Network has slightly higher precision, with fewer false positives, while the Random Forest has better recall, catching more failures with fewer false negatives. This makes the Neural Network preferable in situations where false alarms are costly.
While these results are strong, it’s important to also consider other metrics like F1 score and accuracy, and ensure the dataset is truly representative of real-world conditions. A thorough evaluation ensures that the models provide accurate, practical predictions when applied to unseen data.
4. Smart Traffic Systems
Smart Traffic Systems A Solution to Urbanization and Growing Car Numbers These systems use machine learning, particularly the neural networks to make sure that traffic does not stop unnecessarily and they avoid congestion ensuring all vehicles are landed safely. Machine learning can be applied to variables such as vehicle speeds, counts and traffic patterns, allowing traffic signals and routes to be controlled in real time.
In this section, we take a different track by exploring the prediction of traffic congestion with feedforward neural networks (FFNN), which offers well-known pattern recognition characteristics of FFNN for Smart Traffic Systems━the improvement of traffic conditions in these systems. By using techniques like k-fold cross-validation and hyperparameter tuning, the models are not only accurate but are also generalizable to a variety of different traffic scenarios.
As models are fine-tuned, Smart Traffic Systems will be able to more efficiently regulate city traffic ensuring better travel and safer roads.
Problem Statement:
Smart Traffic Systems: Here the aim is to utilize sophisticated machine learning techniques for enhancing Smart Traffic Systems. If the output looks like jibberish, here is our high level objective : Use Neural Network to predict realtime Traffic Congestion data accurately. With the prediction of bottleneck and anomaly traffic, we intend to try removing congestion and increasing security on the road. The main goal is to perform traffic analysis of variables such as average speed, volumes, day of week, time of day to predict and reduce congestion in advance.
Requirements:
1. Machine Learning Integration: Assess how machine learning, particularly neural networks, can be employed to manage and optimize traffic systems. The emphasis is on using predictive analytics to anticipate and address traffic congestion before it
results in gridlock.
2. Traffic Data Analysis: Interact with a representative dataset that captures essential traffic performance metrics. This analysis is pivotal for understanding the dynamics of traffic flow and the factors that contribute to congestion and safety issues. The dataset is available at: https://files.fm/u/776aagwntb
3. Neural Networks Implementation: Implement feedforward neural networks to develop predictive models that can ascertain traffic congestion. This process should consider the complexity of traffic patterns and the high-dimensional nature of the data.
4. Model Validation with k-fold Cross-Validation: Apply k-fold cross-validation to validate the model’s effectiveness. This technique will help ensure the model’s reliability and accuracy in various traffic conditions.
5. Hyperparameter Tuning: Conduct hyperparameter tuning to optimize the neural network’s performance. This fine-tuning is necessary to achieve the most accurate predictions possible.
6. Code Development and Execution: Develop the necessary Python code to preprocess the data, train the neural network, apply k-fold cross-validation, perform hyperparameter tuning, and evaluate the model’s performance.
7. Result Interpretation: Execute the code and critically analyze the results. The discussion should focus on the model’s accuracy in predicting traffic congestion and its practical application in enhancing traffic management systems
Data Loading and Preliminary Analysis
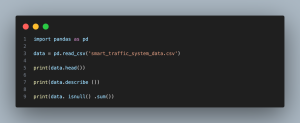
- import pandas as pd: Imports the pandas library, which is pivotal for data manipulation in Python.
- data = pd.read_csv(…): Loads the dataset from a CSV file into a pandas DataFrame. Replace the ellipsis with your file path.
- print(data.head()): Displays the first five rows of the DataFrame. This provides a quick snapshot of the dataset, including the features and target variable.
- print(data.describe()): Generates descriptive statistics that summarize the central tendency, dispersion, and shape of the dataset’s distribution. This helps in identifying any initial data irregularities such as outliers.
- print(data.isnull().sum()): Outputs the number of missing values in each column. Ensuring there are no missing values is crucial before moving on to the preprocessing and modeling stages.
Data Preprocessing
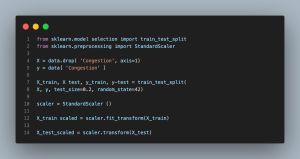
- from sklearn.preprocessing import StandardScaler: Imports the StandardScaler class, which is used to standardize features by removing the mean and scaling to unit variance.
- from sklearn.model_selection import train_test_split: Imports the function to split the dataset into training and testing sets.
- X = data.drop(‘Congestion’, axis=1): Creates a feature matrix X by excluding the target variable ‘Congestion’. This leaves us with only the input features.
- y = data[‘Congestion’]: Extracts the target variable ‘Congestion’ into a separate series y, which will be used to train our model.
- train_test_split(…): Divides the dataset into training and testing sets, with 20% of the data allocated for testing. This is crucial for evaluating the model’s performance on unseen data.
- scaler = StandardScaler(): Creates an instance of StandardScaler to normalize the feature data.
- scaler.fit_transform(X_train): Computes the mean and standard deviation for scaling of the training data, then applies the transformation. This ensures that the model is not biased by the scale of any feature.
- scaler.transform(X_test): Applies the scaling parameters calculated from the training set to the test set.
Model Development with Feedforward Neural Networks
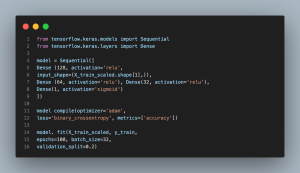
- Sequential([…]): Initializes a sequential neural network model, indicating that layers are stacked linearly. Each layer receives input only from the previous layer.
- Dense(128, activation=’relu’, input_shape=(X_train_scaled.shape[1],)): Adds the first dense (fully connected) layer with 128 neurons. relu activation function introduces non-linearity, helping the network learn complex patterns. The input_shape argument specifies the shape of the input data, matching our feature set’s dimensionality.
- Dense(64, activation=’relu’) and Dense(32, activation=’relu’): These lines add the second and third dense layers with 64 and 32 neurons, respectively. Each uses the ReLU activation function for non-linear transformation of the inputs.
- Dense(1, activation=’sigmoid’): Adds the output layer with a single neuron using the sigmoid activation function. This setup is ideal for binary classification, producing a probability that the input belongs to the positive class (congestion).
- model.compile(…): Compiles the model with the adam optimizer and binary_crossentropy as the loss function, which are standard choices for binary classification tasks. The model will optimize weights to minimize the loss function, with accuracy tracked as a performance metric.
- model.fit(…): Trains the model on the scaled training data (X_train_scaled and y_train) for 100 epochs. The model updates its weights through backpropagation after each batch of 32 samples. validation_split=0.2 reserves 20% of the training data for validation, allowing the model to test its performance on unseen data during training.
Model Evaluation with k-Fold Cross-Validation
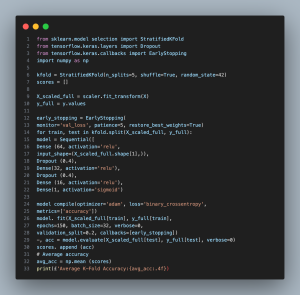
Cross-validation Setup and Execution
- StratifiedKFold(n_splits=5, …): Initializes a StratifiedKFold object with 5 folds, ensuring each fold reflects the class label proportions found in the original dataset. This is particularly important for handling imbalanced datasets effectively.
- kfold.split(X_scaled_full, y_full): This command divides the dataset and targets into training and test groups for each fold, using StratifiedKFold to ensure a balanced representation of classes. It facilitates thorough model evaluation by preserving the distribution of the target variable across folds.
Model Initialization and Training within Each Fold
- Sequential([…]): For every fold, a fresh Sequential model instance is created, allowing the model to be retrained from scratch on each fold’s training data, thus preventing information leakage between folds.
- Dense(64, activation=’relu’, input_shape=(X_scaled_full.shape[1],)): The neural network’s first hidden layer features 64 neurons and uses ReLU activation. The input_shape parameter matches the size of the feature set, tailoring the model to correctly handle the input data.
- Dropout(0.4): After the first and subsequent dense layers, a dropout rate of 0.4 is applied to reduce overfitting by randomly omitting a portion of the layer’s neurons during training, enhancing the model’s generalization ability.
- Dense(32, activation=’relu’) and Dense(16, activation=’relu’): Adds additional dense layers with 32 and 16 neurons, respectively. Both layers employ ReLU activation for nonlinear processing, incrementing the model’s learning capabilities from the data’s intricate patterns.
- Dense(1, activation=’sigmoid’): The final layer is a single-neuron output layer with sigmoid activation, designed for binary classification, outputting probabilities that indicate the likelihood of the target class.
Compilation, Fitting, and Evaluation
- model.compile(optimizer=’adam’, …): Compiles the model, choosing Adam as the optimizer and binary cross-entropy for the loss function, aligning with the binary classification objective. Accuracy is tracked as a performance metric.
- model.fit(…): Adapts the model to the training data of the current fold, specifying 150 epochs and a batch size of 32. The verbosity is set to 0 for simplified output. Validation split and early stopping are employed to monitor and halt training when the validation loss ceases to decrease, preventing overfitting.
- early_stopping: Configured to halt training if there is no improvement in validation loss after five epochs, ensuring efficient training and avoidance of overfitting by restoring the best model weights.
- model.evaluate(…): After training, this function assesses the model on the test subset of the current fold without outputting logs, storing only the accuracy in the scores list for cumulative analysis.
Performance Analysis
- np.mean(scores): Determines the average accuracy across all folds, offering a solid measure of the model’s overall efficacy on the dataset. This metric helps gauge the robustness and reliability of the model’s predictive power.
Hyperparameter Tuning with Manual Approach
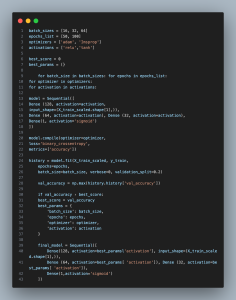
Hyperparameters Definition:
- batch_sizes = [16, 32, 64]: Specifies a range of batch sizes to explore. The batch size influences how many samples are processed before the model is updated.
- epochs_list = [50, 100]: Lists the number of training cycles to test. An epoch represents one complete pass through the entire training dataset.
- optimizers = [‘adam’, ‘rmsprop’]: Enumerates the optimizers to trial. These are algorithms that adjust the neural network parameters like weights to minimize loss.
- activations = [‘relu’, ‘tanh’]: Identifies activation functions for testing in hidden layers, essential for introducing non-linearity to the model enabling it to learn complex patterns.
Comprehensive Visualization of Model Performance
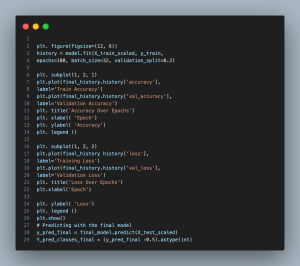
Plot1:Accuracy and Loss over Epochs
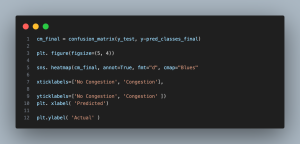
Plot 2: Confusion Matrix
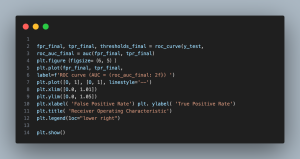
Plot 3: ROC Curve and AUC
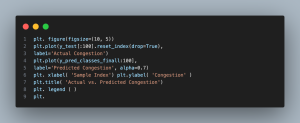
Plot 4: Actual vs. Predicted Congestion
- Plot 1 (Accuracy and Loss over Epochs): This plot tracks the model’s progress by displaying accuracy and loss for both training and validation datasets across each epoch. It is essential for diagnosing the model’s learning process, indicating whether it is learning effectively or showing signs of overfitting (when validation accuracy stagnates or decreases while training accuracy improves) or underfitting (poor performance on both training and validation sets).
- Plot 2 (Confusion Matrix): The confusion matrix breaks down the model’s predictions into true positives, false positives, true negatives, and false negatives. This is useful for evaluating classification performance, including precision and recall, which are critical in contexts where false positives and false negatives carry different costs (e.g., unnecessary interventions vs. missed congestion).
- Plot 3 (ROC Curve and AUC): The ROC curve plots the true positive rate against the false positive rate at various thresholds, while the Area Under the Curve (AUC) quantifies overall model performance. A higher AUC indicates the model’s strong ability to distinguish between congestion and non-congestion scenarios, balancing sensitivity (correctly identifying congestion) and specificity (correctly identifying non-congestion).
- Plot 4 (Actual vs. Predicted Congestion): This plot provides a visual comparison between actual congestion levels and the model’s predictions on test data. It directly illustrates the model’s predictive accuracy, revealing how well it performs in real-world situations and guiding decisions about its practical use in traffic management systems.

The analysis of the ‘Accuracy Over Epochs’ and ‘Loss Over Epochs’ graphs reveals key insights into the neural network’s learning performance and potential real-world application. The accuracy graph shows steady improvement in training accuracy, reflecting the model’s ability to correctly map input features to output. Validation accuracy, though slower initially, follows a similar upward trend, indicating strong generalization to unseen data. However, the slight gap between training and validation accuracy in later epochs suggests the risk of overfitting.
The loss graph tells a similar story. Training loss drops quickly, stabilizing as the model learns. Validation loss, though more erratic, eventually stabilizes, showing the model’s ability to handle complex patterns. The absence of an upward trend in validation loss signals that the model is not overfitting.
Overall, the plateau in both accuracy and loss suggests that further training would yield diminishing returns, making it ideal to halt training and preserve the model’s generalization capability.

The confusion matrix for traffic congestion classification reveals the model’s strong performance, with 118 correct predictions of “No Congestion” and 68 correct predictions of “Congestion.” While the model accurately identifies both conditions, 5 false positives and 9 false negatives indicate room for improvement, particularly in reducing missed congestion events, which could have critical real-world consequences.
The matrix provides insights into the model’s precision—its ability to correctly predict congestion—and recall, or how well it captures actual congestion events. High numbers on the main diagonal reflect the model’s overall accuracy. However, the presence of false predictions highlights the need to balance minimizing false alarms while ensuring that no congestion events are missed.
This analysis emphasizes the importance of refining the model’s sensitivity to congestion, fine-tuning it to meet the demands of practical traffic systems where both precision and recall must be optimized. Enhancing predictive reliability is key to ensuring effective real-world deployment.

The Receiver Operating Characteristic (ROC) curve provides a key performance metric for classifying traffic congestion. It plots the True Positive Rate (TPR) against the False Positive Rate (FPR) at various threshold settings. With an Area Under the Curve (AUC) value of 0.96, the model shows excellent ability to distinguish between congested and non-congested conditions.
A high AUC, close to 1, indicates the model’s strong performance in accurately differentiating between the two scenarios. Most thresholds result in a high TPR with a low FPR, meaning the model effectively identifies congestion while minimizing false alarms. This is crucial in traffic systems where missed congestion events (false negatives) can have significant consequences.
While the model’s FPR is not negligible, the limited number of false positives is manageable given the high AUC. In practical terms, the model is well-suited for proactive traffic management, such as adjusting traffic signals in response to predicted congestion or alerting drivers to potential delays.
This graph compares actual (blue line) and predicted (orange line) congestion levels across several samples, showcasing the model’s accuracy. The close alignment of the lines demonstrates the model’s effectiveness in forecasting traffic congestion. While most predictions closely match actual congestion, occasional deviations highlight areas for improvement.
The value of this visualization lies in its ability to pinpoint both successes and errors. These discrepancies can provide insights for refining the model, such as identifying patterns or times where predictions deviate. Understanding these outliers is key for making targeted adjustments.
For urban traffic systems, a model with strong predictive power like this can greatly enhance real-time traffic management and long-term planning. It could inform decisions on traffic light optimization, infrastructure improvements, and congestion mitigation strategies. However, the model’s robustness in diverse conditions and its ability to adapt to evolving traffic patterns are crucial for real-world application.
I really enjoyed the depth of information in this article!
The site’s usability makes it a pleasure to browse.